AI Engineering
16 min read
The LLM Evaluation Gap: How to Actually Measure What Matters
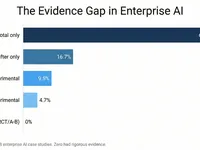
We analyzed 598 AI case studies—zero had rigorous evidence. A practical framework for LLM evaluation: metrics, LLM-as-Judge, RAG triad, and agent assessment.
Read Briefing