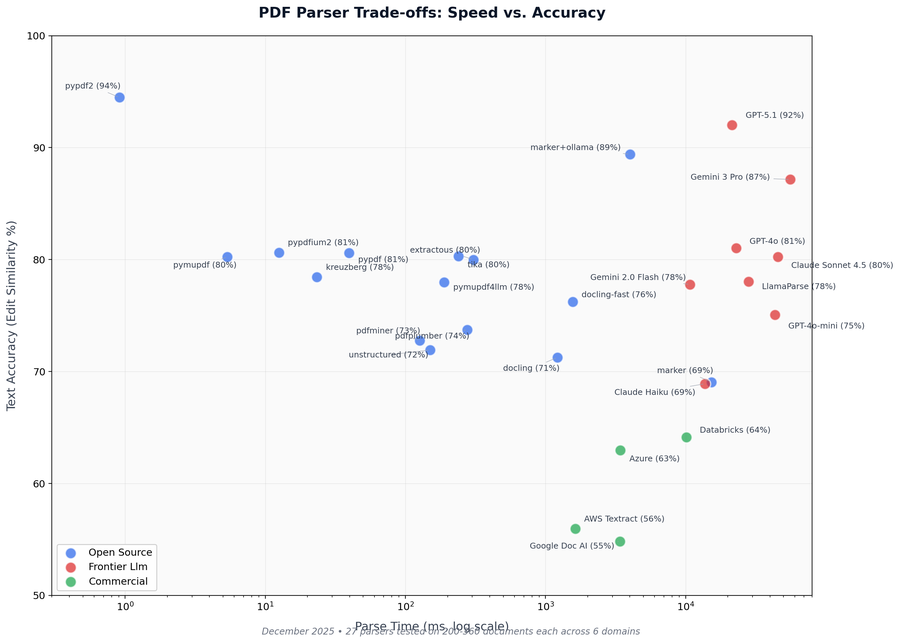
Key Findings
- Top 5 parsers cluster within 1 percentage point (80.3-80.6% accuracy) — the choice barely matters for text extraction
- Speed varies 35,000x: pymupdf (0.7ms) vs marker (14.7s) — pick based on latency budget
- Domain matters more than parser: legal contracts hit 95%+, invoices struggle at 50% everywhere
- Text accuracy ≠ structure quality: a parser can nail text (80%) but destroy hierarchy (40%)
- pdfplumber dominates table extraction at 93.4% TEDS — use it for financial documents
The Benchmark
27 parsers tested on 800+ documents across 6 domains. Six metrics measured independently: text accuracy, structure recovery, table extraction, and speed.
Full methodology, raw data exports, and reproducible evaluation scripts in the repository.
# Clone and run the benchmark yourself
git clone https://github.com/applied-artificial-intelligence/pdf-parser-benchmark
cd pdf-parser-benchmark
uv run python -m pdfbench evaluate --parser pymupdf --corpus cuad